
I have been looking a bit into Unicode and Right-To-Left-Override phishing attacks lately. Mainly because I noticed that Windows Defender was detecting payloads generated with the "—unicode-rtlo" options of MacroPack...
License : Copyright Emeric Nasi (@EmericNasi), some rights reserved
This work is licensed under a Creative Commons Attribution 4.0 International License.
![]()
I. About
I have been looking a bit into Unicode and Right-To-Left-Override phishing attacks lately. Mainly because I noticed that Windows Defender was detecting payloads generated with the "—unicode-rtlo" options of MacroPack tool.
I will not cover all possibilities of Unicode here, its probably a research field and an entire attack surface on its own. So take this as an introduction to some attack possibilities via Unicode.
II. Unicode RTLO attack basics
II.1 What it is?
Unicode RTLO is an attack consisting into spoofing an extension by injecting a Unicode Right-To-Left-Override character (U+202E).
This is possible because Unicode compatible applications will display all char after the RTLO char from right to left.
For example, a file called: example[rtlo]fig.exe would be displayed as "exampleexe.gif" to the user. By changing the exe icon to the one of GIF you can easily guess how this becomes a security problem.
This attack has been around for many years, there are already a lot of resources describing it (such as this one).
II.2 Implementation
Its easy to create a filename spoofing an extension. I included this feature in MacroPack.
For example, lets generate an HTA file running notepad using with a false ".png" extension:
echo "cmd /c notepad.exe" | macro_pack.exe -t CMD -G hello.hta --unicode-rtlo=png
In explorer, the file will appear as "helloath.png" when in fact its really "hello[rtlo]gnp.hta"
III. Bypass AV detection
III.1 Detection analysis
Some time ago I realized that the MacroPack payloads generated with —unicode-rtlo option where flagged by Windows Defender.
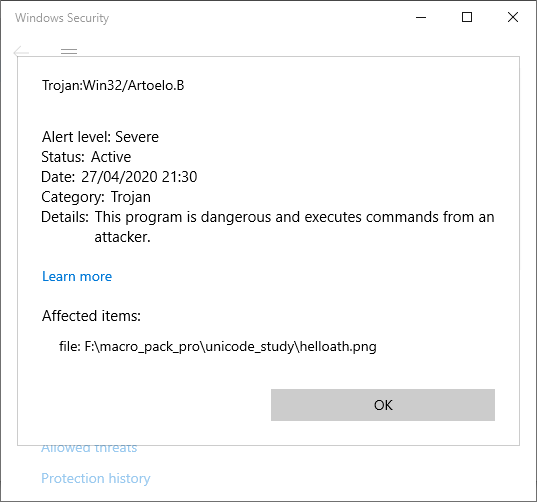
Once I saw that the payload generated with MacroPack was flagged because of its name and not because of its content, I ran a few tests to try to guess what was triggering detection.
I could not be possible that Microsoft just banned the usage of this Unicode char so I wanted to look for a pattern.
Some observed results:
- "hello" + ’\u202e’ + "txt.hta" -> helloath.txt -> flagged
- "hello" + ’\u202e’ + "gepj.hta" -> helloath.jpeg -> flagged
- "hello" + ’\u202e’ + "gnp.hta" -> helloath.png -> flagged
- "hello" + ’\u202e’ + "ggnp.hta" -> helloath.pngg -> not flagged
- "hello" + ’\u202e’ + "ngp.hta" -> helloath.pgn -> not flagged
- "hello" + ’\u202e’ + "gnpa.hta" -> helloath.apng -> flagged
So it appears the detection pattern is: If I have a name of the form "..." + ’\u202e’ + "x.hta"
The payload is flagged as malicious if x ends with a known extension when its letters are reversed from right to left.
III.2 Bypass Windows Defender
Since this attack is only used to lure the user, we just have to find a way that x appears to be a valid extension to the user eye, but not a valid extension to Windows Defender.
The simplest way to do it is simply to add a space.
A payload which is generated the next way is not flagged:
"hello" + ’\u202e’ + "gnp" + " " + ".hta" -> "helloath.png " -> Not flagged!
Below is a python implementation inspired from MacroPack source code which implements this:
IV. Phishing with Unicode characters
IV.1 Spaces and invisible characters
Adding a space may fool users but can still be detected by the cautious eye. Unicode propose a lot of space char from different size, including zero width spaces. Unicode also propose a range of invisible char.
For example, one possibility is to use the U+200B char (Zero-Width Space or ZWSP). It is a space char which is not detectable by the human eye because it has no width!
There are a lot of other char which can be used instead, for example the zero-width non-joiner (ZWNJ) U+200C, but also Zero Width No-Break Space (U+FEFF) and multiple other with or without width (U+2000 to U+200A, U+202F, U+205F, etc.)
Unicode also propose some invisible char such as invisible mathematical operators.
ex U+2064 which is invisible ’+’
Checkout the Wikipedia table for Unicode general punctuation.
As a demonstration, below is a screenshot of a list of files which all have a different name thanks to an invisible Unicode char and use RTLO char to spoof png extension.
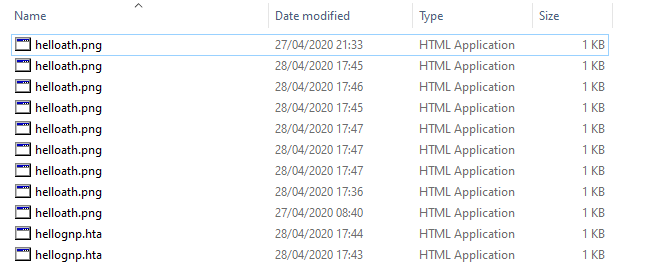
Note the last two files do not appear with PNG extension in Explorer. It seems invisible mathematical operators break Unicode RTLO in Explorer.
IV.2 Homoglyphs
There are other Unicode char which can be used to fool the viewer’s eye. In fact, Unicode supports a lot of alphabets, special char, etc. Some of which are similar to "normal" char. A character looking almost identical to an other is called an Homoglyph.
For social engineering, you can replace a Latin letter by a resembling letter from another alphabet. For example, replace ’i’ by Cyrillic ’і’ (U+0456)
It could be use to fake the extension ".gif" to bypass Defender or other application mentioned in next section.
You can use this homoglyph generator to generate similar looking but different encoding words.
IV.3 Some social engineering applications
Unicode char have been use to spoof domain URLs and file names. I will not cover URL/domains today.
If you want more information on that you can have a look at Wikipedia page on domain names homograph attacks
There is more to say about spoofing file extension spoofing. From the attacker point of view, what is great with this attack is it works across multiple operating systems and applications. However, be aware that from one application to another, Unicode may be interpreted in different ways.
Here is the same list of file from IV.1 viewed from Ubuntu file explorer:
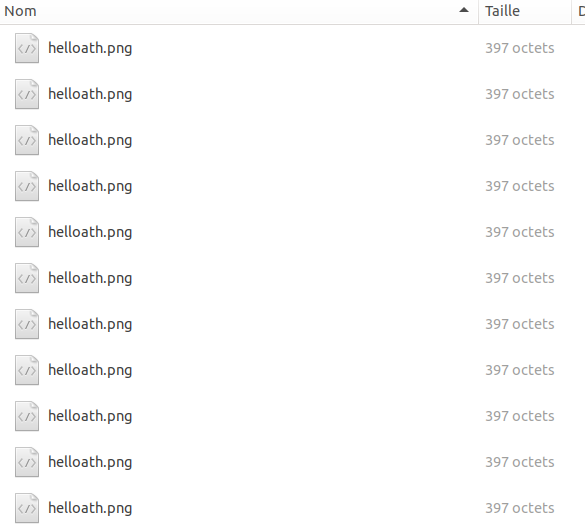
You may notice that in this case RTLO is applied for the last two files (Troll question: Is Linux as a Desktop better then Windows for Unicode? ).
What is interesting is to see how web browsers are affected. Here is the list viewed in Chrome:
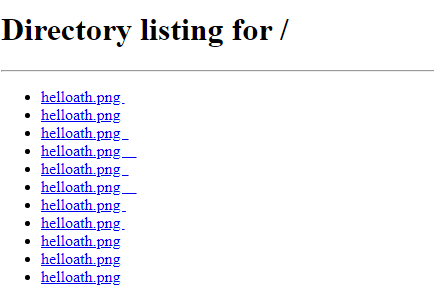
Here is the same list viewed in Firefox:
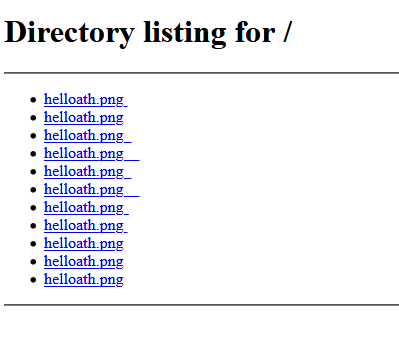
And the same list viewed in Edge:

IV.4 Other offensive security applications
It is possible to use Unicode for stenography and possibly covert channel. As you may have already guessed, there are various ways to hide data in a Unicode message. One simple method is to take two zero width char such as zero-width-non-joiner and zero-width-space. And translate them to 0 and 1 to hide data.
You can find more description and tools about this in the next two links:
- https://hackaday.com/2018/04/15/hide-secret-messages-in-plain-sight-with-zero-width-characters/
- http://zderadicka.eu/hiding-secret-message-in-unicode-text/
V Sum up
While I just wanted to write a bypass for my tool, I had a glimpse to a probably huge attack surface which is Unicode. In addition to all the social engineering risks, we have seen that various application do not process Unicode the same way. This could lead to compatibility issues. Also, Unicode charset is so wide, (it also covers emojis!) there are probably exploitable implementation problems in various applications. I really don’t have the time to look more deeply into that now but I have this other Troll question in mind...
Is Unicode the new JavaScript?